I own UX end to end and drive product direction. I'm at my best at the messy, undefined front of a project, turning "we're not sure what this is yet" into something clear, shipped, and functional.
Research-driven 0→1 builds spanning investigative tooling, information architecture, data visualization, and self-service features. 2023–2026.
The digital world should exist to give us more time back in the real one.
I came to product design by a winding route: years of construction project management and running small businesses. That mix left me fluent in stakeholder alignment, quick to read how a business actually works, and permanently allergic to solutions that ignore it. Most recently, I was sole designer and PM Lead at Spec, a B2B security infrastructure startup — owning UX end to end from problem definition through shipped feature.
As for my real world: I'm a New Orleans native who enjoys good music, good company, and good cooking. When I'm offline, you can find me teaching Ballet, learning about photography, and coaxing the garden through a zone 9 summer.

Drop me a line. I like knowing what people are working on, even when the timing isn't right.
meghan.m.thomas@gmail.comEntity Linking for Investigations

Rebuilding the entity profile — a fraud analyst's view of a single identifier like an email, IP, or merchant ID — into one hub where they investigate and act without leaving the page.
I reviewed Gong call recordings for verbatim client pain points and spoke with the Product Success team who field analyst questions daily. They were the closest proxy to the end user. Finally, I used affinity mapping to turn scattered quotes into themes, and those themes pointed to one surface as the highest-leverage place to start: the Entity Behavior and Linking experience.
Affinity mapping exercise in Excel
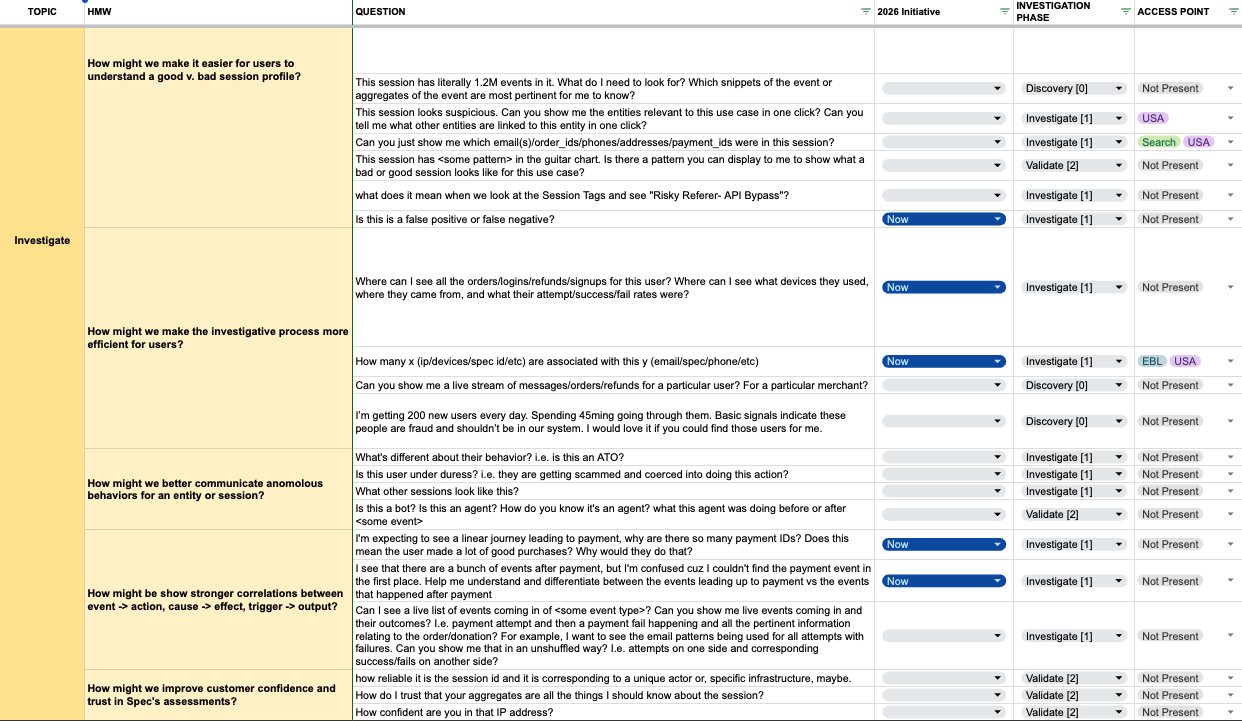
"Where can I see all the orders for this user?"
"How many devices are associated with this email?"
Every question analysts asked was a version of the same one: show me everything tied to this one entity. The tool already had every answer — it just scattered them instead of assembling them into a single story.


Ideating with AI
AI takes the tedium out of ideation, but it doesn't replace the designer: you trade managing yourself for managing an IC only as good as your direction. Used with intention it's a genuine additive; left unchecked, you spend your time fixing its output instead of sharpening your own.

New information architecture layout for the entity profile
The 90-day activity cap wasn't arbitrary: it kept ClickHouse query costs down given Spec's event volume. But 90 days often wasn't long enough to establish behavioral patterns.
Rather than lift the cap, I kept the cost-conscious default and gave users an optional window up to 365 days. Most analysts rarely needed past two or three quarters, so 365 was a deliberate test boundary: enough to validate real demand before expanding further.

Before

After
Every entity shows a status chip (Allowlist, Blocklist, or No List), editable in place and synced both ways with Lists. The same treatment carries through every table, search result, and flyout in the product.

Before

After
A search bar in the side nav lets analysts look up any identifier without leaving context. Live suggestions surface as they type; one click lands in the right profile.
It's arguably the highest-leverage unlock, so why M3 and not M1? Dependencies. A true global search would have been prohibitively expensive at Spec's data volume, so I scoped it with the Product Success (PS) team to a semi-global lookup on key entities. That still needed a new search table from the platform team first, so I sequenced lighter milestones ahead of it and landed it as early as the release chain allowed.

Before

After
Events split into four tables (Payments, Refunds, Logins, Signups), each with tailored columns and breakdowns. A new event_context field lets PS add plain-language explanations to failed events.

Before

After
A node graph surfaces first-degree connections grouped by identifier type, node size scaled to volume. Selecting a node filters the linked entities table and updates the event volume chart live.
This wasn't the first attempt. An earlier graph had been scrapped for good reason: nodes drifted when selected, and color noise buried any pattern. The rebuild was a series of corrections: scope links to first degree, strip the palette, lock the nodes static, and scale each by its event count so volume reads at a glance. From there it hands off to the real analytical work: aggregates, timelines, and click-throughs into event search.

Before

After
Cut on engineering scope and flagged for revisit after launch, recalibrated to whichever clients were actually onboarded by then.
This had to be solved at the session level first. Surfacing it in the profile before that upstream work landed would have shown clients false confidence.

Entity profile

Entity linking
"Awesome!! We have made so much positive progress in such a short amount of time across the board. It's been crazy!!"
Dependencies always shape the order: some work can't ship until its prerequisites exist. Within those constraints, I front-loaded the highest-leverage, lowest-lift pieces, so when the initiative wound down early, the work that mattered was already in users' hands.
Site Sentry

A 0→1 product that maps customer traffic into a visual route table, cutting onboarding from weeks to hours.
I mapped how customer deployments actually worked. Product Success (PS) team interviews exposed a manual, speculative routine: push catch-all specs to see what existed, then reconfigure once the data came back. Sales conversations revealed a parallel gap, Spec was pitched as "proactive," but that proactiveness lived in the process, not the product. Mapping the deployment steps made the root cause plain: with no way to see what routes a customer actually had, every setup started from zero.
"Guess and check. Every time."
You can't configure what you can't see. PS was deploying blind just to learn what was there, so the first thing to build wasn't the config tool, it was the ability to see at all.

The home view is a route table, one row per route key, auto-populated by sampling the proxy. Each row shows the call rate, a 7-day velocity trend, and any deployed spec name and event type. ID-heavy paths compress into wildcards; irrelevant routes are filtered out before they reach the table.

Wireframe

Final
Clicking any route opens a detail view: velocity history, spec name and event type, a breakdown of the route key (URI, query parameters, headers, body), and a real sample request and response from the customer's environment. It answers the question PS used to chase manually: what data is available on this route?

Wireframe

Final
Site Sentry isn't read-only, it's a working surface. PS can full-text search every route for specific cookies, headers, or form keys. Routes split by match criteria or merge via wildcards when ID segments clutter the table. When one's ready to become a spec, its match criteria export as JSON straight into the spec catalog, no transcription, no translation.

Final design
The sampled call rate doubles as an insertion-rate estimate: roughly how many events a new spec will generate before PS commits to it. Teams can now size new coverage before deployment instead of discovering the scale after the fact.

Insertion-rate estimate
It would have blurred a meaningful distinction in the data model. Keeping them separate at launch meant users understood what they were working with, and the upgrade path could be designed deliberately rather than bolted on.

The final route table, annotated
Internal and PS-facing tools shape customer outcomes just as directly as the end-user surface. Designing them with the same rigor, and the same empathy, matters.
Allow / Block Lists

A self-service hub that hands clients all 20 allow and block lists, making time-sensitive blocks instant.
Product Success (PS) team interviews surfaced a constant stream of inbound Slack messages that had nothing to do with their actual expertise. Request pattern analysis showed how lopsided it was: a disproportionate share were simple, repeatable updates clients could easily make themselves. And urgency mapping made the cost concrete, fraud moves fast, but a block only happened when PS was free to action the request.
"Can you add this email to the block list?"
Clients knew exactly what they wanted to block. The product just wasn't letting them do it themselves.

The lists manager lives in a Model Settings tab, opening to all 20 allow and block lists at once, with a filter panel to search by list name or by values inside them, so finding an entry takes seconds. How the lists were grouped came from close work with the PS team, who field these requests daily.

Nav panel

Lists panel
Adding entries supports both the single-value case (one email to block now) and the batch case (200 suspicious IPs). Users type a value or paste a comma-separated list into the same field and press Enter, no separate import modal or upload flow.

Wireframe
Final
Validation catches duplicates across lists and format errors where the element type has a consistent format to check. But it's honest about its limits: some types, like zip codes, vary too much by country to validate reliably, so the product doesn't try.

Error states
The Change Log sub-tab gives clients a full history of every change. Each line is a save event, so updating three lists and saving once groups those changes together, reflecting how it actually happened, especially valuable when multiple team members have access.

Full save history
This would have introduced role-based access control (RBAC), which we weren't ready to tackle in v1.
Paste-and-go covered bulk entry well enough to ship. A file uploader sounds obvious, but "obvious" is just an assumption until someone actually hits the wall. Let real usage ask for it.

The self-service lists hub
Giving clients direct control over something that affects their product behavior means the design has to make them feel confident, not just capable. The interface isn't just functional. It has to feel safe.
Color Palette 101

Spec's first color system: a 12-color chart palette and five semantic states, replacing 50+ scattered hex values.
Color was one layer of a wider audit spanning IA, interaction, styling, and type, and it was impossible to ignore: 50+ disconnected hex values, no shared language, no rationale for any single choice. I don't come from a deep color theory background, so I leaned on outside help. Paul Tol's color research gave me a framework to reason about it; Viz Palette tested color sets in real chart contexts and flagged where shades collapsed or failed accessibility. Then I did all my testing in context, inside real data visualizations rather than swatches, since that's the only way to know whether "distinct" values stay distinct at the sizes and densities they'd actually appear in.
What's mathematically distinct isn't always visually distinct. The eye doesn't read hex codes. Twelve "unique" colors can still collapse into a blur of blues, so the real job was optimizing for perception, not math.

Color was one piece of a broader product audit covering IA, interaction design, styling, and typography. On the color side: every value in the product was catalogued, the inconsistency documented, and then a real research phase began.
I thought I needed 15 colors. After testing in Viz Palette and working through Paul Tol's color-theory research, I landed on 12, with Spec's brand blue as the anchor. This wasn't territory I knew deeply, so I built the foundation first. Accessibility drove it: Viz Palette simulates how a set reads across types of color blindness (deuteranopia, protanopia, tritanopia) and flags pairs that become indistinguishable. Several candidates that looked strong in isolation failed outright, issues no swatch review would have surfaced.

Exploration
The next layer was semantic: colors that communicate risk and status consistently. Five states — red (malicious), yellow (suspicious), green (good), grey (neutral), blue (informational). Yellow was the hardest. It had to read as "suspicious" without veering into orange or washing out too bright to be taken seriously, and landing on one that was unambiguously moderate risk was one of the most important decisions in the system.
The palettes that came close kept hitting the same wall: too similar to a competitor, or to another well-known product. Which raised a harder question: how do you differentiate without diverging for its own sake? Being different just to be different isn't design, it's noise, and noise is the last thing a data product wants. But if a palette is accessible, legible, and already understood, is replicating it actually wrong? That was the quandary, and there's no clean answer, which made it one of the hardest parts of the project.
Where we landed: anchor to meaning. The status colors didn't need to be original, they needed to be correct. Green means good, red means bad, yellow means watch out. Those associations are too deep to fight, and fighting them for the sake of differentiation would only make the product harder to trust. The distinctiveness came from how the system was built around those anchors, not the anchors themselves.

Early exploration

Good (green)

Suspicious (yellow)

Malicious (red)

Informational (blue)
Midway through, a surprise: Spec rebranded with a new brand blue and purple, and the palette went back to the drawing board. The goal expanded from updating chart colors to building a full system: 8 color families (red, orange, yellow, green, blue, purple, pink, grey), each with stops up and down to support a future dark mode. Brand blue and purple subbed in directly; grey was edged toward Spec's blue tones to keep blacks off true black; red and green carried over from Phase 2. The one exception: the risk yellow stayed protected. It had taken too long to find and was too precisely calibrated to touch. Four accent colors for chips, icons, and categories were defined here too.
With the expanded palette defined, the Phase 1 validation ran again: every color through Viz Palette for distinguishability and accessibility. The rebrand introduced values never tested in data-viz contexts, so this wasn't a formality — new blue, new purple, and adjusted neutrals all had to hold up at small sizes, in overlapping series, and across the impairments the tool flags. Some needed nudging, some passed clean. The color report became the record of what was intentional and what was a known tradeoff.

Color report
A color system without usage guidance is just a swatch set. This layer defined how each category applied across UI contexts — backgrounds, borders, icons, text — with clear rules for where each role belonged. It also set up a future dark mode: the stop structure across each family was designed so that wouldn't start from scratch.

Border
Icon

Text
The existing chart palette was good enough to hold, so the overhaul was deliberately paused: better to fold it into the eventual redesign of the Insights experience and its core charting aids than to rebuild the chart colors in isolation.
A matter of time, not priority. The system was fully defined in Figma; codifying it as tokens in code was slated to build with the front-end team during the next innovation week.

Colour primitives

Colour primitives, continued
The hardest question wasn't which colors to pick — it was whether choosing familiar ones was a failure of nerve. It wasn't. Green means good, red means bad; those associations run too deep to fight, and fighting them for originality's sake would only make the product harder to trust. The distinctiveness came from how the system was built around those anchors, not the anchors themselves.
Insights Experience

Turning a passive analytics Hub into one that surfaces what changed, before users even know to ask.
The Product Success (PS) team knew the sessions worth watching, the trends, the patterns that mattered per customer, but none of it lived in the product. A new-user audit showed the cost: people arriving at the Hub had no way to see what was happening without already knowing what to ask, so the product rewarded expertise it couldn't assume. A second chart-interaction audit surfaced a related gap: nearly every chart was a dead end. Only the Session Volume Timeline let you click through to search; everything else forced users to rebuild the query by hand.
"They are great examples of why we need to make the product clean for clients. They will actually be using it."
That gap — a powerful tool with no guidance — surfaced in three different ways over three years, and each became its own phase of work.
The original Insights experience: powerful, but it required you to arrive with a question.
The foundation. Before Custom Dashboards (2024) and chart click-through (2025) could build on it, the core experience had to exist: a starting point assembled from the PS team's knowledge of what mattered to each customer. What follows is that founding effort, end to end: explore, converge, ship.
With the PRD in hand, I moved into the design space to make sense of it: roughly translating requirements into Figma, pulling screen inspiration from products solving adjacent problems, and pressure-testing how the insight cards and overall layout could come together. The goal was to explore widely before committing: how insights should be grouped, what belonged on the first screen, and how each metric should read at a glance.

Screen-inspiration research: pulling patterns from adjacent products
The exploration converged on a deliberate narrative arc: the broadest view at the top, narrowing down to the most granular. At this time, the product was communicating user journeys at the session and lightly at the event level. Every chart became a doorway into the underlying data for each use case that was sold to the customer in the form of 'modules'.

Information architecture: the broadest view at the top, narrowing to the most granular.
From there the structure resolved into concrete wireframes, then got checked against the original experience to make sure nothing in the PRD was lost.

Lo-fi user flow: the full path from insight list through overview and detail, out into search.

Old vs. new, checked against the PRD so nothing was lost
The experience shipped as a single progressive drill-down. The Insight List grouped session and event trends, each showing its week-over-week change and a 7-day trend, color-coded so problems read red and wins read green. Clicking an insight filtered the Session Volume Timeline to the relevant sessions and events in that use case.
The shipped Insights experience: the Insight List and its progressive drill-down.

States: the loading, empty, and populated states behind each surface.
Curated beats flexible. Most users don't want to build their own dashboards — they want someone to have already decided what's worth watching.
The original page was session-centric, but customers thought in events and entities, and PS kept fielding questions session-based reporting couldn't answer. Custom Dashboards handed that flexibility to PS: with a JSON config and a ClickHouse SQL query against the event and entity data, they could spin up any visualization a customer needed (refund reasons, top cities, high-velocity IPs) and white-glove each account without an eng ticket. An internal-only flag let them build and vet privately first. Just as useful, it doubled as a low-cost testing ground for which visualizations customers actually reached for — signal to de-risk a future overhaul. No new design was needed here; the charts reused the existing library, so my role was to test as engineering built it out.

Custom event and entity charts, added to the Insights structure.



Custom dashboards PS configured per customer — refund reasons, top cities, high-velocity IPs, and more.
By 2025 the architecture had grown: the original drill-down plus Phase 2's custom event and entity charts. One gap remained — most of it was a dead end. Only the Session Volume Timeline could be clicked into; every other chart left analysts to rebuild the query by hand. The V2 release made the whole structure navigable: clicking any chart opened a filtered Event Search in a new tab, each insight defining which columns the drill-down surfaced. Little of this needed new design; the interaction reused existing patterns. My role was stewardship — making sure engineering reused the chart library and color scales so it stayed consistent, and testing in staging before it shipped.

By 2025, every chart links out to its relevant search — session, event, and entity.
"[The flow is] cumbersome… Don't always have 45 minutes to analyze something."

A chart click-through lands in a filtered Event Search, its filter carried in as a pill.
Curated grouping already covered the core need. Letting users build their own was a power-user refinement that could wait until demand asked for it.
Compelling, but it leaned on search-infrastructure work that wasn't scoped yet — a dependency to sequence, not a design gap.
The existing library shipped every phase without blocking anything. A more sophisticated upgrade was a larger investment, better folded into a future overhaul.
The goal was never to hand users more analytical tools — it was to lift the analytical burden off them entirely, so that arriving without a question was still productive, not a blank page. Every phase was a version of the same move: take knowledge that lived in someone's head or behind a manual export, and build it into the product so the user didn't have to.